Many of you are likely to have been following the recent news (see here and here and here and here for recent articles) on facial recognition software, its use in the criminal justice system, and the systematic racial biases associated with facial recognition. You may also be aware of other algorithms which are systematically biased against a particular group of people.

However, you may not have a plan for how to bring the ideas into the data science classroom. Below we provide a series of examples and connections to data science and statistics curricula that can help students connect course topics with the world around them.
Biased data lead to poor models
The number one problem with algorithmic bias comes from bias in datasets. A model is thought to be good if it approximates the data on which it was built. The whole point of a model is to describe a given dataset! A model is no good if it doesn’t represent the data, which leads to the conclusion that any algorithm needs to be built on data which does not have systematic biases or underrepresentations.
Of course, much of the world we live already systematically disadvantages certain groups of people, so even “random samples” can lead to algorithms that reinforce structural biases. One hugely impactful recent research study describes the inability of off-the-shelf facial recognition software to differentiate the gender of an individual if their skin is dark.
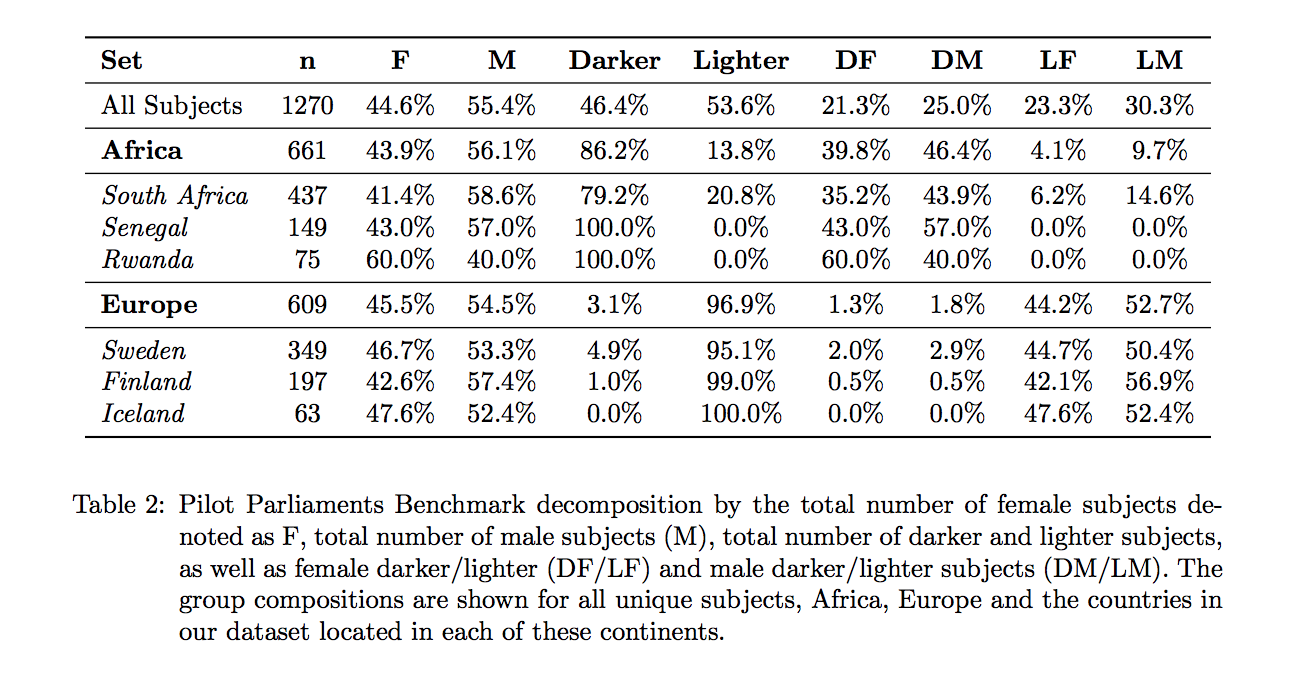
Many other examples exist. Below is a series of translation of Turkish into English. Where Turkish pronouns are gender-neutral, the translations below magnify our cultural biases about women’s roles, men’s roles, and stereotypical gender personalities.

Serious ramifications
Algorithmic bias isn’t just an academic problem. It is a problem with serious consequences for marginalized people.
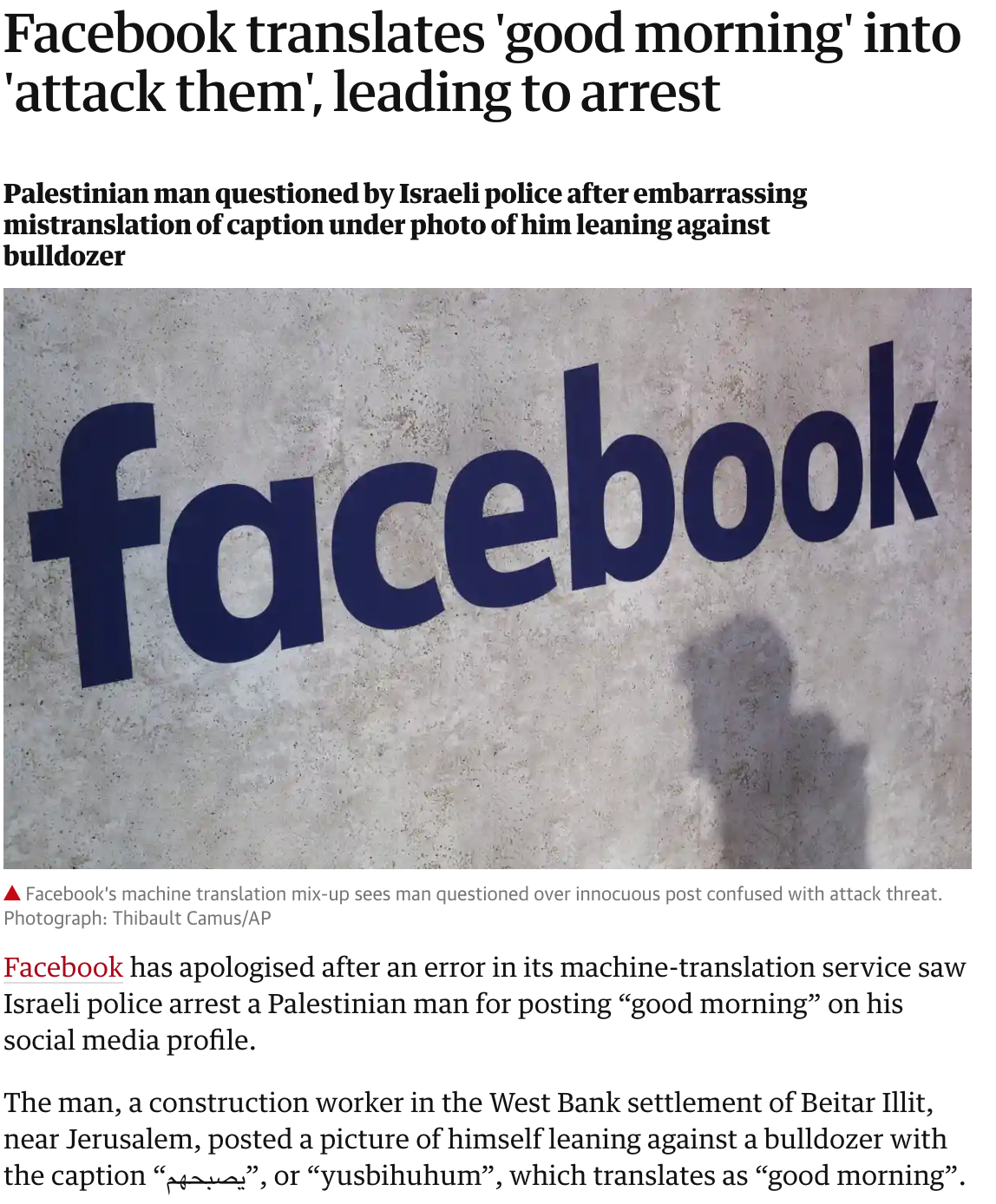
- Poor translation led to the arrest of a Palestinian man who posted good morning on his Facebook account.
- Facial recognition software is being used to determine the amount of insurance you can purchase.

- The COMPAS algorithm which is used throughout the country to determine recidivism produces extremely different false positive and false negative rates across gender. If you teach about COMPAS and the ProPublica investigation, you might consider introducing the mathematics behind constraints on false positive, false negative, and accuracy rates as shown by Chouldechova.

Math as a weapon
A number of recent books describe how math and algorithms can be weaponized to appear impartial but to have a disproportionately negative impact on marginalized peoples.

- One of the chapters in Weapons of Math Destruction discusses algorithmic credit scores. O’Neil’s argument is underscored by work in the law field describing how algorithmic credit scores seemingly violate the Fair Credit Reporting Act, Selling Consumers, Not Lists: The New World of Digital Decision-Making and the Role of the Fair Credit Reporting Act by Mierzwinski and Chester.

- Automating Inequality discusses how automated decision-making creates a “digital poorhouse” that perpetuates the existing economic biases against marginalized people. We end the blog entry with a quote from the text. We agree with Eubanks that as data science educators it is a vital part of our job to communicate to our students that their work has real impacts for real people.
As we create a new national narrative and politics of poverty, we must also begin dismantling the digital poorhouse. It will require flexing our imaginations and asking entirely different kinds of questions… What would decision-making systems that see poor people, families, and neighborhoods as infinitely valuable and innovative look like? It will also require sharpening our skills: high-tech tools that protect human rights and strengthen human capacity are more difficult to build than those that do not.
In the classroom
There are also good curricular materials that can help you incorporate algorithmic bias and ethics into your own classroom. Check them out for additional resources, out of class experiences (e.g., homework or research projects), and connections between data science topics and real world experiences.
- Baumer, Kaplan, and Horton’s Modern Data Science in R has a free Chapter on data ethics
- Barocas, Hardt, and Narayanan have detailed formal non-discrimination criteria in their on-line textbook Fairness and Machine Learning
- Miles Ott posted his slides from Symposium on Data Science and Statistics 2019 Incorporating Data Ethics in a Statistics / Data Science Major
- Fantastic discussion of biased algorithm with very telling unbiased (!) simulation Algorithmic Unfairness Without Any Bias Baked In
- Brianna Heggeseth & Leslie Myint Ethical Considerations from Introduction to Statistical Modeling.
- The Belmont Report
- Ethics and Policy in Data Science, INFO 4270 at Cornell University
- A Cource on Fairness, Accountability, and Transparency in Machine Learning
- CS 294 at UC Berkeley Fairness in Machine Learning
Learn more
- The Institute for Ethical AI & Machine Learning
- The real reason tech struggles with algorithmic bias
- Ethics in Machine Learning, an Interview with Dr. Hanie Sedghi, Research Scientist at Google Brain
- The National Artificial Intelligence Research and Development Strategic Plan: 2019 update
About this blog
Each day during the summer of 2019 we intend to add a new entry to this blog on a given topic of interest to educators teaching data science and statistics courses. Each entry is intended to provide a short overview of why it is interesting and how it can be applied to teaching. We anticipate that these introductory pieces can be digested daily in 20 or 30 minute chunks that will leave you in a position to decide whether to explore more or integrate the material into your own classes. By following along for the summer, we hope that you will develop a clearer sense for the fast moving landscape of data science. Sign up for emails at https://groups.google.com/forum/#!forum/teach-data-science (you must be logged into Google to sign up).
We always welcome comments on entries and suggestions for new ones. However, comments on the blog should be constructive, encouraging, and supportive. We reserve the right to delete comments that violate these guidelines.