What are Projects?
RStudio Projects are a mechanism for keeping all the files associated with a project together in one place – data, R scripts, results, figures, reports, etc. Projects are built in to the RStudio IDE, and for good reproducible workflow, all projects should start by creating a Project.
Why RStudio?
It goes almost without saying that as a group we have moved completely to the RStudio interface to R. We made the switch years ago and have never looked back.
RStudio is an integrated development environment (IDE) that provides a more coherent and consistent interface to R that is well suited to experts and novices. It is available in both open source and commercial editions on Windows, Mac OS X, and Linux. (We will talk more about the cloud (server) interface in a future entry.)
For those not using (and teaching with) RStudio, we strongly urge you to make the switch.
Why use Projects?
The NASEM report on data science (see blog entry at https://teachdatascience.com/nasem/) discussed the importance of workflow and reproducibility as one important component of data acumen. Their list of key concepts includes:
- Workflows and workflow systems,
- Reproducible analysis,
- Documentation and code standards,
- Source code (version) control systems, and
- Collaboration.
We will discuss many of these topics over the coming weeks, but wanted to start with the use of projects to help students begin to think more holistically about workflow.
Projects provide a simple way to isolate work on a single analysis and to organize files and datasets.
Keeping track of data
Generally, the working directory is the place where R looks for files (most importantly, data files). If you aren’t using a project, you will likely need to setwd in your RMarkdown or R script file before running your R code. However, if you send your code to someone else, then (a) they need to change the filepath that you set to a local place on your own computer, (b) you have to remember to send the exact data file. We strongly discourage ever using the setwd command.
An alternative to setwd() to a local path on your own computer is to keep the data in a specified place within your Project so that you can pass the entire project to your collaborator (ideally using collaborative software like Git).
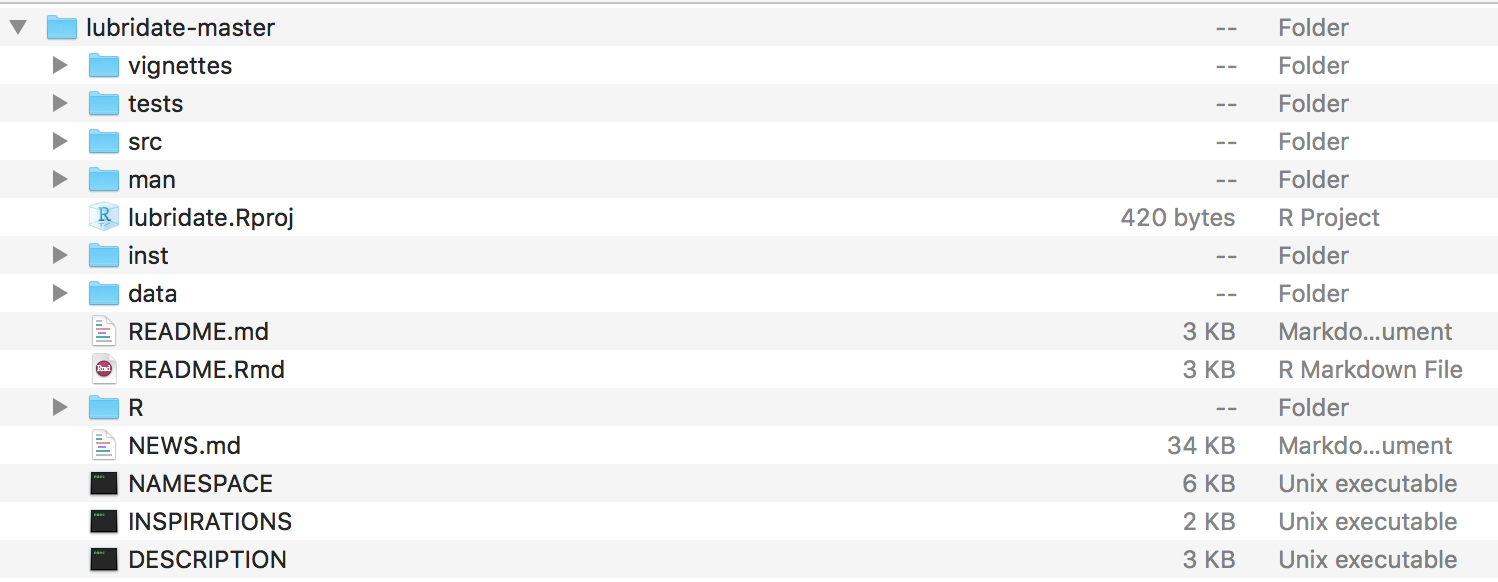
Below is the file structure from the R package lubridate (taken from downloading the package code from GitHub). The file lubridate.Rproj keeps track of where all the other files reside. Data live in the data folder, R code lives in the R folder, etc. When opening lubridate.Rpoj within RStudio, the script files will automatically be directed to the appropriate working directories within the lubridate Project.
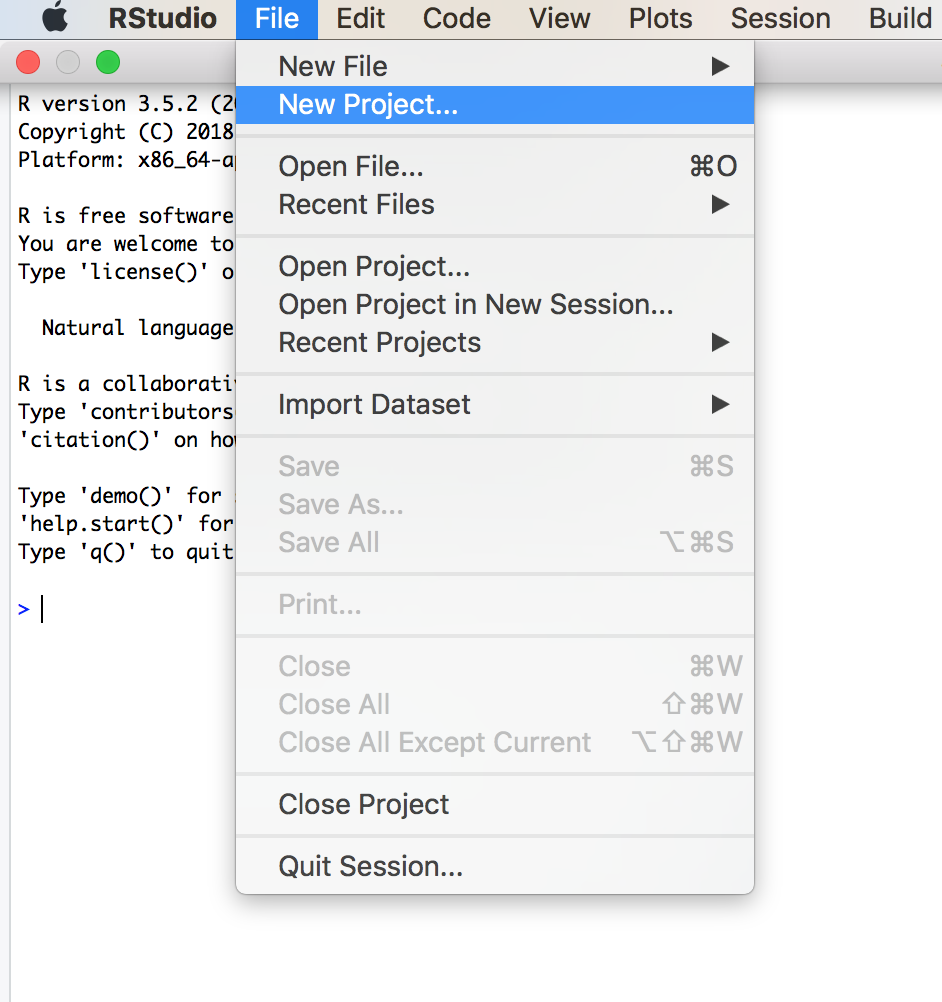
Creating projects is easy
Before starting a new project, select New Project to create a space for all of your work to live. Then start on your research by writing R code or R Markdown reports.
RStudio Projects and GitHub
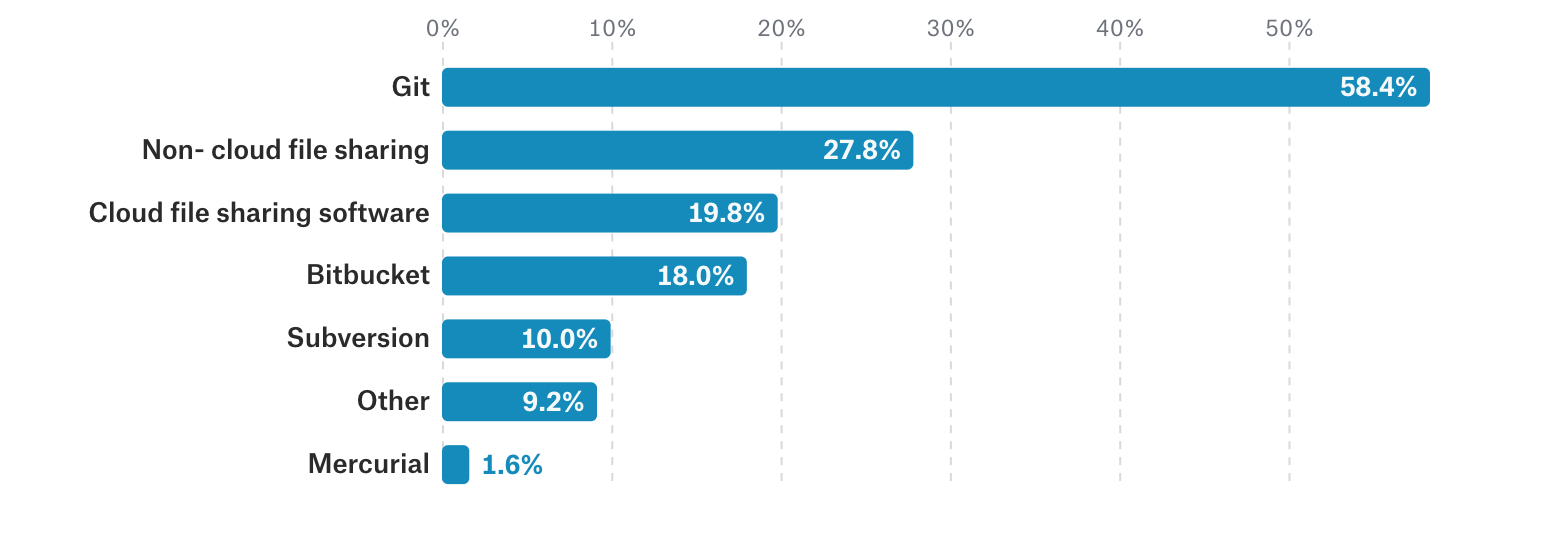
Another important reason to work with Projects is that they work easily within the most used code sharing software, Git. Of the respondents to the Kaggle 2017 survey, 58.4% responded that Git is how code is shared at work. https://www.kaggle.com/surveys/2017. (We’ll return to Git in a future entry.)
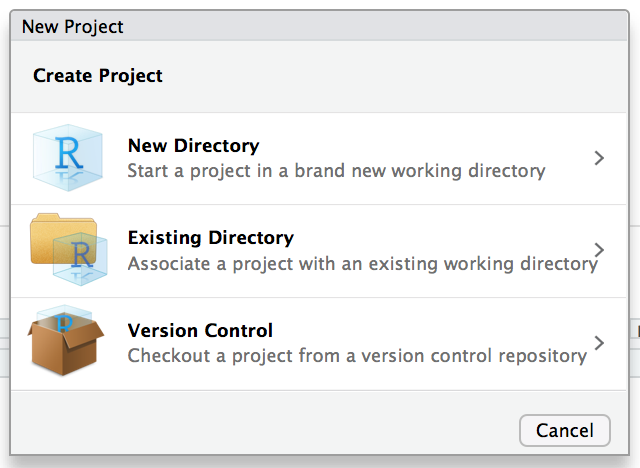
The options for creating a new project in RStudio include a new folder, an existing folder, or a version control (e.g., GitHub) software. By seamlessly saving the entire project in a Project, updates to data or source code get updated along with the update to the actual code. By organizing research into Projects, the chance of breaking the reproducibility chain is minimized.
Learn more
Basics of R Projects (for those new to R) from Jenny Bryan’s Stat 545 course: http://stat545.com/block002_hello-r-workspace-wd-project.html
Jenny Bryan’s evolving thoughts on Project-oriented workflows: https://whattheyforgot.org/project-oriented-workflow.html
Workflow: projects in R for Data Science https://r4ds.had.co.nz/workflow-projects.html
RStudio support for projects: https://support.rstudio.com/hc/en-us/articles/200526207-Using-Projects
More on Workflow (and the evils of
setwd): https://www.tidyverse.org/articles/2017/12/workflow-vs-script/
About this blog
Each day during the summer of 2019 we intend to add a new entry to this blog on a given topic of interest to educators teaching data science and statistics courses. Each entry is intended to provide a short overview of why it is interesting and how it can be applied to teaching. We anticipate that these introductory pieces can be digested daily in 20 or 30 minute chunks that will leave you in a position to decide whether to explore more or integrate the material into your own classes. By following along for the summer, we hope that you will develop a clearer sense for the fast moving landscape of data science. Sign up for emails at https://groups.google.com/forum/#!forum/teach-data-science (you must be logged into Google to sign up).
We always welcome comments on entries and suggestions for new ones.