About pandas
pandas is an open-source library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. Straight from the library’s homepage, “pandas helps fill Python’s long-standing gap in tools for data analysis and modeling.”
In short, pandas offers some new and some improved Python tools for doing the following:
Reading data in to data frame-type structures
Viewing and selecting data
Handling missing data
Performing (more) SQL-type operations like group-by operations, merging, and reshaping
Combining and wrangling time series data
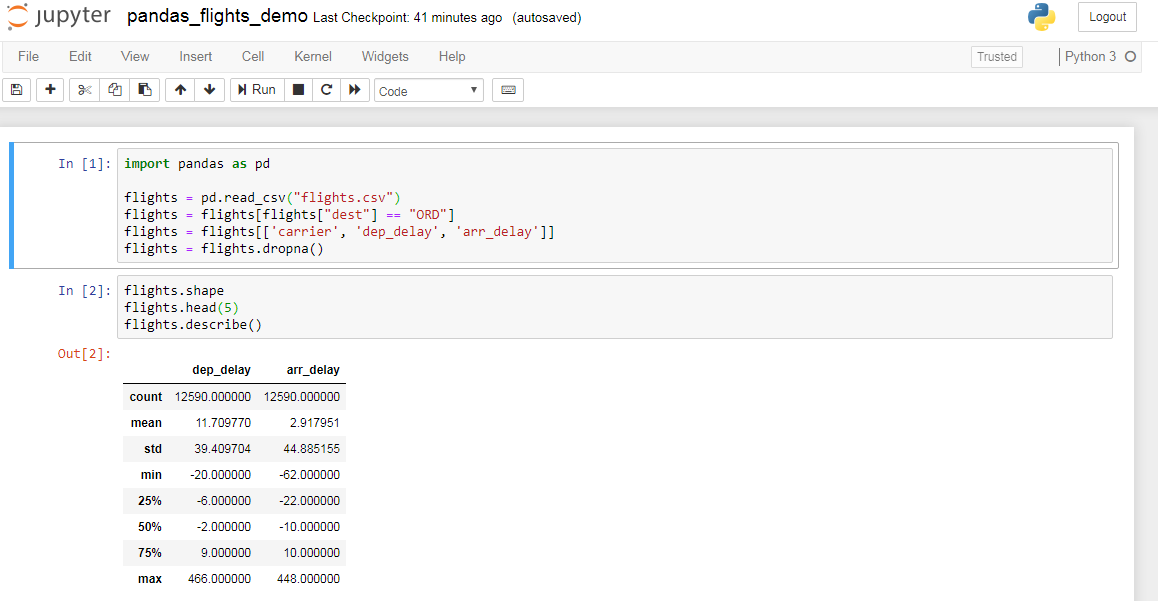
Let’s start by using a bit of the pandas library to look at the flights dataset (here in a Jupyter Notebook, see our blog entry on Jupyter Notebooks):
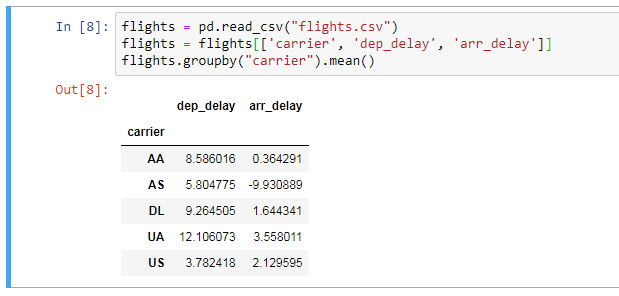
To demonstrate the method chaining possible along with the aggregation functionality mentioned above, let’s compute the average departure delay and average arrival delay for each carrier.
If you’re unfamiliar with methods (in Python), you can think of them as being similar to functions but with the following properties:
a method is called by its name, but it is associated to an object (dependent)
a method is implicitly passed the object on which it is invoked
it may or may not return any data
a method can operate on the data that is contained by the corresponding class
whereas, say, functions are not associated to an object – they are independent. Methods exist in multiple languages, but are quite popular in Python.
The method chaining above should be reminiscent of the piping found in our discussions about the Tidyverse, but this has always been a style of programming possible with pandas. Even so, dplyr, pandas, and many other packages out there continue to help inspire each other and evolve together.
Teaching Data Science with Python
Data science with Python does not stand on the pandas library alone. There are a number of other Python libraries that have become widely popular for doing data science. In particular the libraries below, along with pandas, will give you in Python what a great deal of the Tidyverse provides you in R:
For more advanced statistics and machine learning there are even more libraries out there.
Learn more
While pandas is arguable a Python staple in a data scientist’s toolkit, there are many other Python libraries widely used throughout the data science workflow. This post was just a taste of what pandas helps Python bring to the table. Numerous resources exist for more information and tutorials on the full functionality of pandas:
Cheat sheet: https://github.com/pandas-dev/pandas/blob/master/doc/cheatsheet/Pandas_Cheat_Sheet.pdf
Modern Pandas tutorial: https://github.com/TomAugspurger/effective-pandas
pandas collection of tutorials: https://pandas.pydata.org/pandas-docs/stable/getting_started/tutorials.html
pandas introduction: https://towardsdatascience.com/a-quick-introduction-to-the-pandas-python-library-f1b678f34673
Blog entry on Jupyter Notebooks
About this blog
Each day during the summer of 2019 we intend to add a new entry to this blog on a given topic of interest to educators teaching data science and statistics courses. Each entry is intended to provide a short overview of why it is interesting and how it can be applied to teaching. We anticipate that these introductory pieces can be digested daily in 20 or 30 minute chunks that will leave you in a position to decide whether to explore more or integrate the material into your own classes. By following along for the summer, we hope that you will develop a clearer sense for the fast moving landscape of data science. Sign up for emails at https://groups.google.com/forum/#!forum/teach-data-science (you must be logged into Google to sign up).
We always welcome comments on entries and suggestions for new ones.